Several weeks ago a gray fox and her kits took up residence on the Facebook campus and have since garnered quite a lot of attention amongst employees and thepress. Despite not actually having seen them “in the flesh” myself, the foxes are one of those special moments that show up in my News Feed and put a smile on my face.
The photos and videos of the little fox family have also captured the interest of my kids — they gush every time I share the latest with them. And because my daughter is currently quite enchanted with LEGO, the foxes are an opportunity to unleash my own inner child (read: dork) to make something special for her.
So with that in mind, the other night I put together a custom LEGO fox kit using the free LEGO Digital Designer app and I’m making it available to anyone who wants to build their own. The kit contains the complete parts list with piece IDs for LEGO’s Pick-a-Brick service along with detailed step-by-step visual assembly instructions.
When I moved the Notebook site over from the wishingline.com domain over to this one, one of the things I wanted to do was rebuild the contact form from scratch and integrate it into the base Movable Type install that manages things behind the scenes.
That was a fairly simple process overall and using a bit of PHP, jQuery and Ajax magic, I built the form so that it works whether Javascript is enabled in the browser or not. Unobtrusive progressive enhancement — it’s good. You should try it.
Where I ran into a problem though was that all of a sudden bots were going to town on the form and I was getting all kinds of spam through the form, despite work put into preventing that at the start — e.g. ensuring the form would only accept local requests from the same domain, using secret server-level key validation, etc.
Ultimately what proved to cure the problem: give the fields unusual names. If you have a field that collects a person’s name, don’t name it “name” or an email address, “email”. Bots look for that and can easily exploit it.
Truth be told: I knew this. Maybe you already do too, but an occasional reminder never hurts.
Last year when I originally moved the Wishingline site and a handful of others over a shiny new slice at Slicehst one of the issues I ran into was handling outgoing mail from contact forms, Movable Type, etc. I’m no server admin and despite knowing enough to be dangerous, setting up a secure mail server that can handle multiple domains was definitely outside my comfort zone.
Thanks to Ethan, I discovered a gem of an open source project called MSMTP which was just what I needed; the exception being that I couldn’t figure out how to use it with multiple domains. Until last week that is.
Of course it’s really easy.
Installing and Configuring for Multiple Domains
MSMTP provides two ways you can configure the software using a simple and well-documented configuration file format. It’s all plain text so it’s easy to create, edit and back up.
Installing the Software
Installing MSMSTP requires the following packages which can be installed using the aptitude tool on Ubuntu. Installation on other *nixes may vary.
Once you have everything installed, you need to create a configuration file either in /etc/msmtprc or by creating a user-specific one in your user’s home directory. If you need mail services for more than one domain, I suggest using the global configuration option.
I’m going to assume you’re reasonably comfortable working in a Unix environment from here on out though if you know what you’re doing you can do all of this just as easily using ExpanDrive and TextMate without having to touch the Terminal.
$ sudo nano /etc/msmtprc
Once the nano editor has opened a new blank file for you, enter the following and replace the example configuration as needed. I’m including examples for two domains so you get the idea.
# Account: domain1.com
account domain1
host smtp.gmail.com
port 587
auto_from off
auth on
user hello@domain1.com
password PASSWORD
tls on
tls_starttls on
from robot@domain1.com
maildomain domain1.com
tls_trust_file /etc/ssl/certs/ca-certificates.crt
logfile
syslog LOG_MAIL
# Set a default account to use
account default : domain1
# Account: domain2.com
account domain2
host smtp.gmail.com
port 587
auto_from off
auth on
user hello@domain2.com
password PASSWORD
tls on
tls_starttls on
from robot@domain2.com
maildomain domain2.com
tls_trust_file /etc/ssl/certs/ca-certificates.crt
logfile
syslog LOG_MAIL
Repeat as necessary to add more domains. Save your changes by typing Control-O and pressing Enter. Then type Control-X to exit the editor.
Virtual Host Configuration
Assuming you’re using PHP with Apache as your web server, you can add the last two lines in the example below to each virtual host to specify which configuration account you’d like to use to send mail.
<VirtualHost *:80>
ServerAdmin webmaster@domain1.com
ServerName domain1.com
DocumentRoot /home/user/sites/domain1/
DirectoryIndex index.html index.php
# MSMTP configuration for this domain
php_admin_value sendmail_path "/usr/bin/msmtp -a domain1 -t"
</VirtualHost>
Replace domain1 with the correct domain obviously. This should correspond to the account names specified in the /etc/msmtprc file.
Alternatively you need to instruct your middleware or framework to use MSMTP instead of Sendmail/Postfix to send mail and pass the same account parameter whenever called. Most have some form of configuration option to allow this.
For the past few weeks we’ve been working on designing and building out a site for a client and since selecting Movable Type 4 as the CMS, we thought it would be worth giving the relatively new Virtual MT a try as part of our development process. Although our overall experience using VMT so far has been great, we ran into one small nit: the default site isn’t served from the root URL of the server and instead uses a subdirectory path. This (probably) should be a user-defined option, but isn’t currently, so we set out to resolve this for ourselves.
Let’s be honest — Movable Type has always been a bit of a pain to run on Mac OS X unless you happen to be or know someone well-versed in the black art of the command line and Perl. A black art if you’re a designer at least. This is exactly why VMT is great, particularly if you’re already used to running Windows in Parallels or VMWare for browser testing and debugging.
Virtual MT comes pre-packaged as part of a lightweight Ubuntu Linux OS. Downloading and running an instance (or multiple instances) of VMT is simple and we’ll cover the process using Parallels 4 before walking through the configuration change to allow the default site to be served from the root path of the included Apache web server.
Downloading and Running VMT
Get started by downloading a copy of Virtual MT which comes in both Open Source and Commercial (Pro) flavours. Unzip the downloaded archive and read the included Read Me file. No really, read it.
Parallels Virtual Machine list
Next, locate the VM Image file for Parallels (or your preferred Virtual Machine software) in the unarchived folder in your Downloads directory. In the case of Parallels, this file should end with a .pvs extension. Double-click the file to add it to the Parallels Virtual Machine library. Parallels 4 will request the VM image be converted to the newer bundle format.
The Virtual Machine book screen in Parallels
Click on the Virtual Machine and start it. In a web browser, go to the Configuration Page URL displayed in the running Virtual Machine window.
The running Virtual Machine window in Parallels
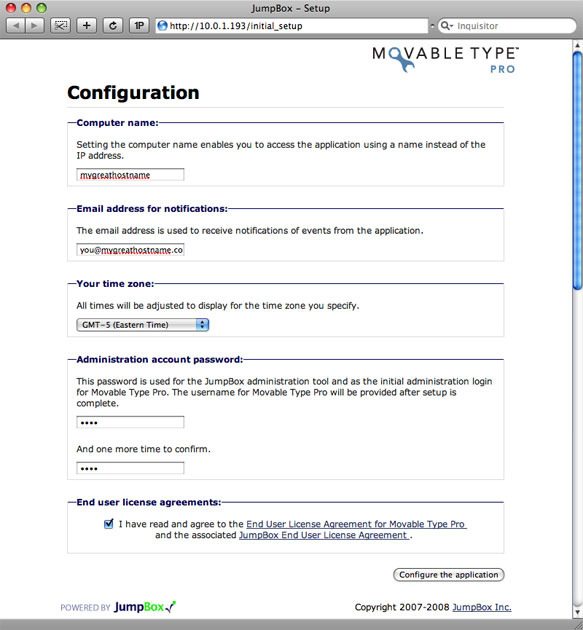
Complete the base configuration to enable access to the VM and Movable Type itself.
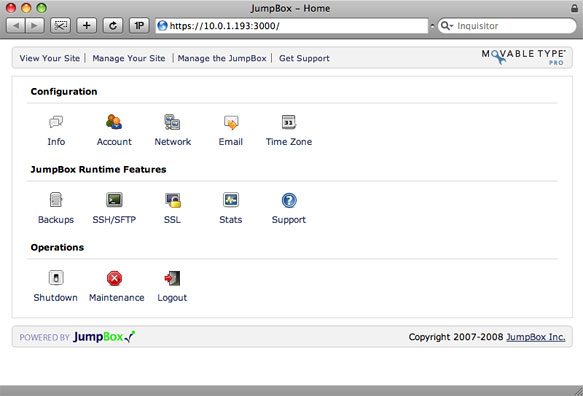
The configuration screen for the Movable Type JumpBox
Once the base configuration is complete, go back to the main Configuration Page and click on the SSH/SFTP icon. Check the checkbox to enable SSH/SFTP access and then save the change.
The Movable Type configuration home screen
At this point you should have a fully functional, ready to customize virtualized install of Movable Type. No mucking about in the command line or Perl module installation required. Next — improving the configuration.
VMT Configuration Changes
In order to “correct” the configuration of VMT, provide access to the VMT install at the root of the included Apache web server and make accessing the MT insall and any published templates easy, you may want to install either MacFuse or ExpanDrive which let you access the virtual OS filesystem just like any other shared disk. Alternatively, Transmit or any other software that supports SFTP connections will also work, though direct access in the Finder is considerably more user-friendly.
And now the nerdy part. To make the necessary Virtual Machine configuration changes, run the following two commands in a new Terminal window. Replace VIRTUAL_IMAGE_IP_ADDRESS with the one provided in the VM window on your computer.
After entering your admin password when prompted, in the pico text editor, change the contents of the jumpbox-app file to match the following:
# Alias /movabletype/blogs /var/data/mt-blogs
Alias /movabletype /var/data/movabletype
<Directory /var/data/movabletype>
AddHandler cgi-script .cgi
Options +ExecCGI
# Uncomment the following lines to enable FastCGI
# <FilesMatch "^mt(?:-(?:comments|search|tb))?\.cgi$">
# SetHandler fastcgi-script
# </FilesMatch>
</Directory>
<Directory /var/data/mt-blogs/*>
AllowOverride All
</Directory>
# Uncomment the following lines to enable FastCGI
# FastCgiServer /var/data/movabletype/mt.cgi
# FastCgiServer /var/data/movabletype/mt-search.cgi
# FastCgiServer /var/data/movabletype/mt-tb.cgi
# FastCgiServer /var/data/movabletype/mt-comments.cgi
RewriteEngine on
# RewriteCond /jumpbox/var/widget-on !-f
# RewriteRule ^(/?|/index.(html|php|htm))$ /movabletype/blogs/my_blog [R]
# RewriteCond /jumpbox/var/widget-on !-f
# RewriteRule ^/jblogin.(html|php)$ /movabletype/mt.cgi [R]
# DocumentRoot /var/www
DocumentRoot /var/data/mt-blogs
Save your changes by typing Control-O and then Control-X. To then restart Apache so it will reload the newly updated configuration, type the following in the Terminal.
sudo /etc/init.d/apache2 restart
Updating Movable Type’s Publishing Paths
The last thing that needs to be done is to update the Publishing Path values for each blog instance in Movable Type so content will be published to /var/data/mt-blogs instead of the default location. This is done from the Preferences > Publishing screen in the Movable Type admin interface.
Set the value of Site URL to the IP address of the VM and set the Site Root to /var/data/mt-blogs. If running more than one blog instance, change these values apporpriately. Save the changes and re-publish. And that, as they say, is that. Enjoy!
Note: The current (as of this writing) release of Virtual MT is slightly out of date with the recent 4.23 release of Movable Type though it’s simple enough to update your own base install in VMT.
One of the things that annoyed me with the process of setting up a Subversion server with SSH access, aside from the sheer complexity, was the number of steps required just to create a new project. Once was bad enoug, but repeating those steps each time to create a project just didn’t scale…
So, a bit of Bash scripting later and everything is much, much easier.
Assumptions
The instructions and script that follow assume you completed the earlier tutorial carefully when setting up your own Subversion server. It may not be appropriate or work as expected otherwise. As always, YMMV.
Creating, Configuring and Using the Script
Somewhere in your $PATH on the system acting as your Subversion server (I suggest /usr/local/bin), create a new file named svnproj, set the file as executable and then finally open the file for editing.
#!/bin/sh
REPOSITORY="/svn" # Set to your repository path
USER="admin_user" # Set to your system admin user
# ====================================================
# Do not change anything below the line above
PROJECT_NAME="$1"
if [ $# -eq 0 ] ; then
echo "Usage: newproj PROJECT_NAME"
exit
fi
echo "------------------------------------------------"
cd ${REPOSITORY}
svnadmin create ${PROJECT_NAME}
echo "Created project: '$PROJECT_NAME'"
echo "Configuring svnserver.conf for restricted access"
cp ${REPOSITORY}/${PROJECT_NAME}/conf/svnserve.conf \
${REPOSITORY}/${PROJECT_NAME}/conf/svnserve.conf.default
cat > ${REPOSITORY}/$PROJECT_NAME/conf/svnserve.conf << "EOF"
[general]
anon-access = read
auth-access = write
[realm]
realm = Projects
EOF
echo "Successfully set svnserve.conf"
chown -R ${USER} ${REPOSITORY}/$PROJECT_NAME
chmod -R 770 ${REPOSITORY}/$PROJECT_NAME
chmod g+t ${REPOSITORY}/$PROJECT_NAME/db
echo "------------------------------------------------"
echo "Done"
The script requires you to set two internal variables in order for it to actually work; one which sets the location of your repository, and a second which sets the admin username on your system which will be the default owner of files and folders in the repository. You can find these at the top of the script, named REPOSITORY and USER respectively.
Running the script is as simple as:
sudo svnproj PROJECT_NAME
If you happen to run the script without the PROJECT_NAME parameter, it will simply output the usage note and exit gracefully. Whether you need run the script via sudo ultimately depends on where your repository is located on your server.
Our particular version of this script does one additional thing — it creates a post-commit hook script and automatically inserts the necessary code to output commit messages as an RSS feed per these instructions.
As Wishingline has slowly grown beyond just one person, the need to change workflows and improve our ability to communicate and collaborate with clients, peers and partners has prompted us to do things a bit differently than in the past. One of these things has been to set up our own internal Subversion server. Yeah — we know git is the new hawtness, but the tools available and integrating git are few, and honestly, our own experience with it has not left us paricularly enamoured.
In setting up a new Subversion server for us to use internally, secured on our network, but also accessible remotely, we started off with our own tutorial from back in 2007, a bit of help from the official Subversion book, and our old friend Google. We ran into a few problems along the way, and so in the hopes of saving others from running into the same issues, this entry will hopefully serve as a straightforward and complete guide to setting up a Subversion server using svn+ssh authentication on Mac OS X (Client and/or Server).
Prerequisites
In order to complete everything below on your own systems, you will need:
At least two Mac systems: one which will act as a central Subversion repository (server) another as a development workstation.
Mac OS X: Leopard 10.5.x (ideally 10.5.5) Client or Server. There’s a good chance that you’ll be able to follow this guide on Tiger as well, but YMMV.
Xcode 3.0 or newer, included on the Leopard install DVD, included with the iPhone SDK and otherwise available free from the Apple Developer Connection site.
A sufficient degree of comfort in working in the Terminal application.
Administrative access.
A few Notes Before we Start
Nearly all the instructions to follow require extensive use of the Terminal application which can be found in the /Applications/Utilities folder on your Mac. Each line in the code examples that follow should be entered into the Terminal and followed by the Return key.
Setting Up Your Envrionment
As with other Unix operating systems, Mac OS X uses the PATH environment variable to determine where to look for applications when working on the command line. It’s common to install custom builds of Unix software in /usr/local in order to avoid interfering with core system software. A big benefit being that you don’t have to worry about updates to Mac OS X inadvertently overwriting your custom software installs.
To set your the PATH for your user account on your workstation, you will need to either create or edit a .bash_login file which is commonly used to customize the default shell environment on a per-user basis. To open or create the file, in the Terminal, type:
pico ~/.bash_login
If the file does not exist, the following needs to be added at the end of the file in order to set the necessary PATH variables so that you will be able to use the various Subversion applications without needing to specify the full path to them on your systems.
The one oddball in the above PATH is the path to the aliasbin directory. We’ll explain what that’s all about later on. Patience grasshopper!
Save and close the file by typing Control-O and then Control-X. You’ll be returned to a new prompt in the Terminal. Close the window and open a new one to load your changes.
Xcode and Subversion
When you install Xcode 3.0 or newer, a version of Subversion (at the time of this writing, version 1.4.4) is also installed. Although you could use this version and skip a few steps, this tutorial is based on using the latest and greatest.
Step 1: Installing Subversion Prerequisites
Before installing Subversion there are a number of prerequisites which can or should be installed depending on your specific needs. In this particular case, the only one necessary is zlib which is used to add compression support to Subversion.
In order to keep things neat and tidy, source downloads can be saved to the Downloads folder in your home directory or wherever you prefer.
Installing zlib
To download, compile and install zlib, type the following in the Terminal:
cd ~/Downloads
curl -O http://zlib.net/zlib-1.2.3.tar.gz
tar -zxf zlib-1.2.3.tar.gz
cd zlib-1.2.3
./configure --prefix=/usr/local
make && sudo make install
cd ..
Once you get to the sudo make install command, you should be prompted for your administrator password. Enter that when requested in order to complete the installation.
Installing neon
If you want or need WebDAV support in Subversion, you can also install the neonHTTP and WebDAV client library. neon is entirely optional, but if you want to install it, type the following in the Terminal:
cd ~/Downloads
curl -O http://webdav.org/neon/neon-0.28.3.tar.gz
tar -zxf neon-0.28.3.tar.gz
cd neon-0.28.3
./configure --prefix=/usr/local \
--enable-shared=yes \
--with-ssl=openssl \
--with-libxml2
make && sudo make install
cd ..
At this point you should now have the two primary prerequisites installed, meaning you’re now ready to download, build and install Subversion itself.
Step 2: Installing Subversion
Compiling Subversion with all the necessary support libraries is straightforward. If you did not install neon as in the prerequisites above, be sure to omit that line in the configure command below.
cd ~/Downloads
curl -O http://subversion.tigris.org/downloads/subversion-1.5.4.tar.gz
tar -zxf subversion-1.5.4.tar.gz
cd subversion-1.5.4
./configure --prefix=/usr/local \
--disable-mod-activation \
--with-apxs=/usr/sbin/apxs \
--with-ssl \
--with-zlib=/usr/local \
--with-neon=/usr/local \
--without-berkeley-db \
--without-sasl
make && sudo make install
cd ..
You should now have Subversion installed on your system(s) in /usr/local/. You can verify this by checking the version of one of the Subversion applications. Type svn --version in the Terminal.
In order to create a complete client-server configuration with remote repository access, you will need to complete Steps 1 and 2 on both Macs. If you’ve got more than two Macs, repeat as necessary.
Step 3: Workstation Public/Private Key Creation
Public/private keys can be used to secure your network communications even more than relying on simple password authentication. In this particular case, these keys can be used to provide secure authentication to your repository. To create a public/private keypair, in ther Terminal, type:
cd
mkdir ~/.ssh
ssh-keygen -t rsa
If you do not want to use a passphrase as an extra level of security, just press Enter when prompted. The ssh-keygen command will create two files in the .ssh directory, ida_rsa.pub and ida_rsa.
The first, with the .pub extension is your public key which you’ll need to copy to the Mac acting as the repository server into a file named authorized_keys. The second is your private key. Do not share this with anyone. Seriously. The private key will be unique to each system/user and identifies that particular Mac when authenticating to the server or to any other systems sharing the public key. Simply put, in order to authenticate successfully, you need both halves of the key.
Step 4: Setup Users and Groups on the Server
There’s a few different ways users and groups can be managed: the Accounts system preferences panel, the command line and the Mac OS X Server Admin Tools which can also be used on the consumer version of Mac OS X and not just the server edition.
Launch the Workgroup Manager application from the /Applications/Server folder and press the Cancel button when prompted to login to the server. Instead, select View Directories from the Server menu and click the lock icon on the Workgroup Manager window to authenticate yourself as an administrator.
Create a Subversion Users Group on the Server
Before users can be given access to the repository, users all need to belong to a common group which will have read/write permissions for the repository on the server.
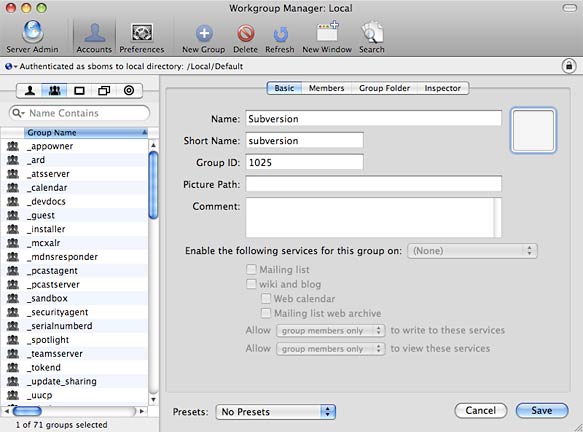
Creaing a new group in Workgroup Manager
Click on the Groups tab to switch to the Groups view and then click the New Group button to create a new group. Give the group a Name and Short Name and press Save. Click on the Members tab to add users to the group or switch to the Users tab and add users to the group from there. Depending on how many users you need to provide access to, one method might be faster than the other.
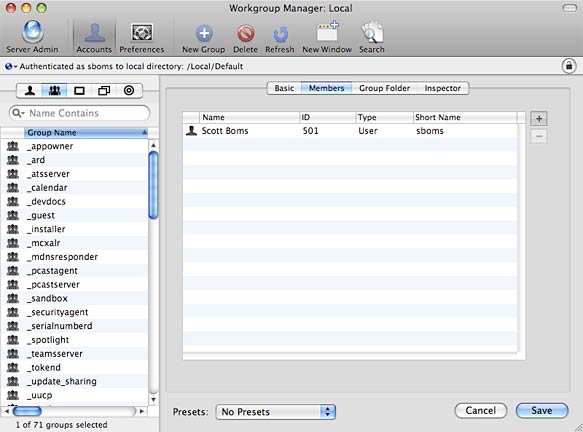
Adding members to a group in Workgroup Manager
Create User Accounts on the Server
Unlike other Subversion authentication methods (file://, svn://), accessing a repository via SSH requires that real user accounts exist on the server. In theory at least, these users should be able to access the server via SSH as any other user, though this can be restricted. More on that later.
Create any needed user accounts by clicking on the New User button in Workgroup Manager.
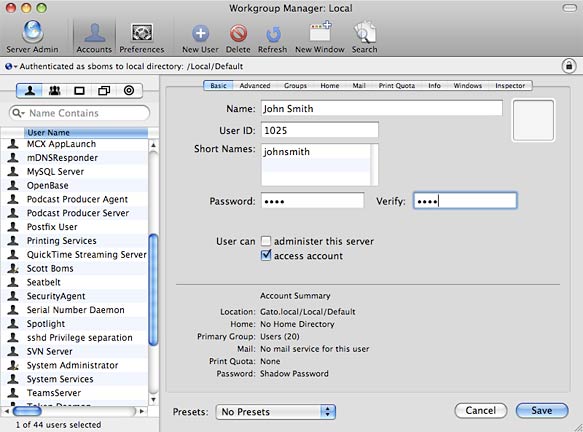
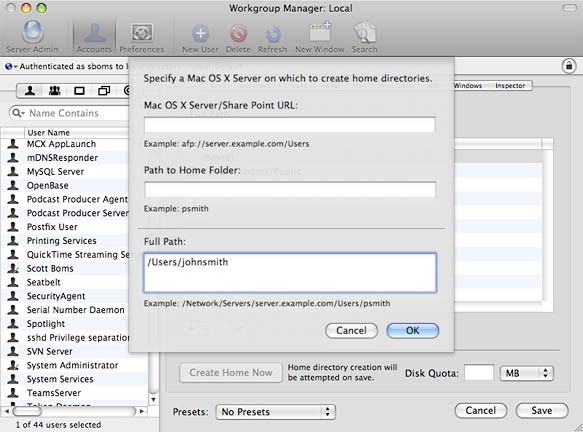
Creating a new user account in Workgroup Manager
Under the Basic tab, enter a Name, Short Name, Password, and set Administrator Access. Under the Home tab, press the Add button and enter /Users/USERNAME in the Full Path field and press Ok. Save your changes and click the Create Home Now button. This should create a new user just as if you did so using the Accounts preference panel in System Preferences and also generate their home directory.
Setting a user’s home directory in Workgroup Manager
To finish configuring access for each user to allow passwordless access using their individual public/private keypair, the user’s public key needs to be copied to an authorized_keys file in a .ssh folder in their home directory on the server.
Copy each user’s public key file to the server into their home directory. Exactly how you do this isn’t particularly important, but putting the key in the right place, named correctly and with the correct permissions is.
The cat command will take the contents from a file named id_rsa.pub and append it to the end of a file named authorized_keys or create a new file if it doesn’t exist. Repeat for each user needing access the Subversion server and replace USERNAME with the appropriate value. You can do this from a single administrative user account or by logging in as each individual user in sequence.
If a user has more than one computer which may require access to the repository, you can include more than one public key in the authorized_keys file; just ensure each is on it’s own line. Using the cat command above will do just that.
Step 5: Secure SSHD on the Server
Out of the box on Mac OS X, SSH is relatively secure, but there’s more we can do to improve it’s resiliance, particularly on the server side of things. To enhance the security of the server, edit the /etc/sshd_config file in the Terminal.
cd /etc
cp sshd_config sshd_config.orig
sudo pico sshd_config
Locate and edit the following list of configuration properties for the SSHD daemon process so they appear as shown below. Press Control-O, then Control-X to save the changes.
Protocol 2
PermitRootLogin no
PasswordAuthentication no
X11Forwarding no
UsePAM no
UseDNS no
AllowUsers [list of users -- see Step 4]
The list of users to be allowed should be based on the user’s short name and separated by a space. Note that you can skip changing the PasswordAuthentication setting if you may need to provide password access.
Note: If you need to add a new user later, you will also need to add that user to the AllowUsers setting in the sshd_config file and restart the SSH process on the server. Also, if you really want to secure things a bit more, change the default port to something other than 22. The catch is that you will have to include the custom port as a parameter when connecting via SSH.
Step 6: Create Aliases of the Subversion Applications
In case you were wondering… this is where we get really nerdy.
To allow more than one user commit access to the repository, when logging in via SSH, each authenticated user will run their own instance of the svnserve process on the server. As such, the process needs to run with a specific umask in order to prevent permission problems.
There’s two things we need to do in order to make this work:
Create a few simple shell scripts that run the appropriate svn application using the required umask. This should be done for svnadmin, svnlook and svnserve.
Then in the pico editor, type the following. Replace svnserve in the example with each of svnadmin, svnlook and svnserve.
#!/bin/sh
umask 002
/usr/local/bin/svnserve "$@"
Press Control-O and then Control-X to save your changes, quit the editor and return to a new prompt. Finally, set the necessary ownership and permissions on the scripts.
In order to ensure that the new svnserve alias is used when a user is interacting with the Subversion server, a special command must be prefixed before each public key listed in a user’s authorized_keys file.
sudo ~USERNAME/.ssh/authorized_keys
Replace USERNAME above with the specific user’s shortname.
Replace USERNAME above with the specific user’s shortname and note that the command above should be added on a single line with no line breaks, including the entirety of the public key. The value of PUBLIC_KEY should be the existing public key. Save the changes by pressing Control-O and then Control-X.
Step 8: Create a Repository on the Server
You’re most of the way there now… You’re now finally ready to create a new repository and project to test things out. The basics of this are no different than if you were using basic file:// or svn:// methods to access the repository.
Note that you shouldn’t need to specify /usr/local/aliasbin before the svnadmin command because you should have that included first in your PATH variable. If you haven’t done that, go back to step one before proceeding any further.
To create a new repository and versioned project at the root of the server and set the necessary permissions (though technically you could really put this anywhere you wanted on the system), simply execute the following, replacing SVN_USERS_GROUP_NAME with the name of the group set in step four:
The above commands create the repository directory itself, create a new test project (named “test_proj”) and then set the necessary permissions. The one critical command above is the last one which sets a sticky bit on the project’s “db” folder which ensures that permissions are maintained, particularly since more than one user will have write access to the project. This will save you frustration in trying to sort out why a second user all of a sudden cannot commit a change to the repository…
Finally, in order to secure the project so that only authorized users can read and write to it, you should edit the svnserve.conf file for the project and set the appropriate permissions as below. By default anyone who can login to the server should be able to access the repository in a read-only state, but no one has write access. This is clearly not right, so let’s fix that.
Press Control-O and then Control-X to save your changes and return to a new prompt.
At this point you should have a basic project created and the necessary permissions set to ensure that all users will be able to access it as needed. A caveat to repository access using svn+ssh is that there is no mechanism to restrict access to only specific users on a project by project basis unlike other methods which provide simple facilities for this using configuration files. These configuration files are not used when accessing a repository via svn+ssh.
Note that when you create a new project in your repository, repeat the process of creating the project as illustrated above. You can obviously skip the step of creating the actual repository directory itself.
Step 9: Check out Your Test Project
That’s it. Everything should be set and ready to roll. You can test that your Subversion server is configured properly by performing a simple checkout of your test project.
In a Terminal window on your local workstation, type:
cd ~/Sites
svn+ssh://USERNAME@IP_OR_HOSTNAME/test_proj
If all goes well, the project should download securely over SSH to the Sites folder on your Mac workstation. You’re then free to test committing a change back to the server.
If things work the way they should (cross your fingers), you should see a message indicating your change was committed to the server as version 1.
Wrapping Up and Final Notes
Setting up secure access to a Subversion repository is not for the faint of heart as it turns out and hopefully you made it this far.
As noted earlier, there’s a few other things you might want to know about how things are configured. You’re best to grab a copy of the official Subversion book and read through the relevant chapters. In particular, although you’ve provided secure access using public/private keypairs and set a command value in the authorized_keys file which otherwise prevents normal SSH access into the server, it is possible that a user could gain SSH access through other methods. In order to provide as few permissions as possible, you may want to set a few more restrictions by setting additional options immediately after the command in the authorized_keys file. You can read more on this on page 168 in the official Subversion book.
Questions, comments, or errors/typos in any of the above can and are encouraged to be noted in the comments. Finally — as with any such tutorials, YMMV.
Leopard, despite having 300 new features being promoted has still managed to tuck away a few more interesting and useful tricks which are now slowly being uncovered. A couple such useful features revolve around what might be one of my favourite new features - screen sharing.
Basically Apple included a full VNC client right into the core of Leopard; something previously only available either via third-party apps or Apple’s own Remote Desktop. If you haven’t tried it, find a friend running Leopard, connect via iChat and share your screen or connect to theirs. Cool, no?
Screen Sharing toolbar in Mac OS X 10.5
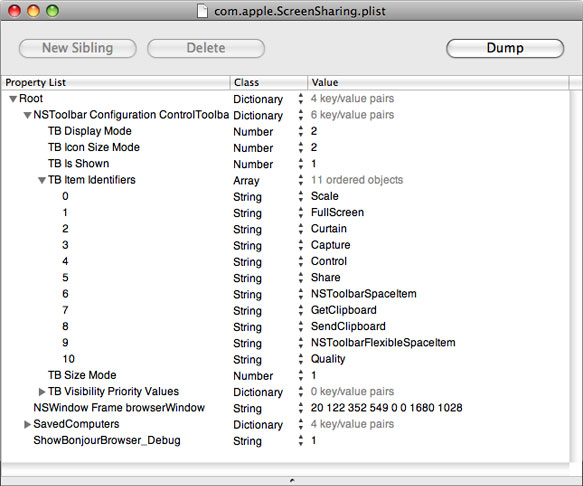
But there are a few more hidden features tucked away in the System/Library/CoreServices folder on your drive. The first is a browser view to see any active systems via Bonjour. You can access this by running a simple defaults command in the Terminal and then opening the Screen Sharing application which you can find in that CoreServices folder.
The browser may be a bit buggy which would explain why it’s disabled by default, but it’s handy nonetheless. On top of this, you can also access a number of other useful features via the toolbar in the screen sharing app window which bring it a few steps closer to Remote Desktop such as Full-screen mode, Control the other screen, Share Control of the other screen, Capture (take a screenshot), Curtain and adjust Quality. Adding these is simply a matter of editing the application plist file which you can find in your Preferences folder.
Open the com.apple.ScreenSharing.plist file using the Property List editor (installed with the Xcode developer tools included with Leopard) and expand the list items to show the following.
In starting (somewhat) fresh with this new version of the notebook, one critical thing on the list of must do items was to finally do away with the old popup window style comments. These were a throwback and perhaps unfortunate decision made when this site was first built on Movable Type 2.x and I chose to use monthly archives as the primary archive type instead of individual entries. Hindsight is 20/20 I’ve heard…
Upgrading to Movable Type 4 and cleaning out the attic presented an opportunity to rectify this problem. The primary archive type used throughout, now individual entries, allows inline commenting without requiring popup windows. Changing the commenting behaviour provided a second opportunity — to allow the use of John Gruber’s Markdown syntax instead of vanilla HTML in the comments, something I’ve wanted to do for some time now.
Essentially this means dropping in plain old links in the comments will be converted but will definitely receive the rel="nofollow" treatment.
My reasoning is simple. One — I use it myself. Every post in the notebook has been written using Markdown. Two — it’s easy to learn, use, and has the right amount of syntax flexibility in terms of what I’m willing to allow.
Movable Type 4 blog comment settings
While setting up commenting to allow Markdown formatted comments I discovered a problem: certain parts of Markdown’s formatting syntax were being ignored and converted into plain text. My first thought was that this was a bug in either Markdown or in Movable Type itself, but after a bit of digging using Google and in the documentation for Movable Type itself, I recognized the problem.
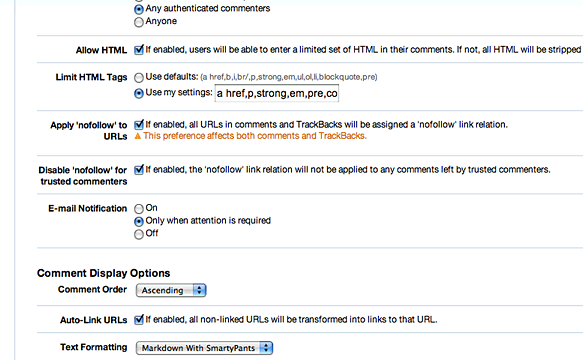
Out of the box, Movable Type’s comment feature will only allow certain HTML tags to be included. Anything else will be automatically stripped out — for example: code, blockquote, h4, h5, h6. To change this behaviour, it’s simply a matter of specifying your own subset of HTML elements which will be acceptable in comments and setting the appropriate text filter in the Movable Type blog comment settings. The specific details on how to do this are:
In your blog’s comment settings, choose Markdown for text formatting.
Click the “Allow HTML” checkbox to enable comments to accept plain old vanilla HTML.
Under the “Limit HTML Tags” options, use your own settings to specify the tags you want to allow in comments.
Uncheck the “Allow HTML” checkbox one you are finished entering tags in step 3. Save your settings and rebuild you entries.
Although I haven’t tested this, I suspect the same procedure will also work if you choose to use Textile formatting for comments.
Leopard is out and it’s generally good aside from a few minor hiccups, surprises and unexpected changes deeper down in the OS affecting the Unix core.
One such hiccup is that the native bindings that allow Ruby and MySQL to communicate are a bit harder to get working than in Tiger unless you happened to just go a straight upgrade to Leopard in which case they should still be working.
Once you’ve got that installed along with the Xcode Developer Tools (found on your Leopard DVDs in the Optional Installs folder) you are ready to fire up the Terminal and install the MySQL Gem. You’ll be prompted for your admin password after the first command.
sudo -s
ARCHFLAGS="-arch i386" gem install mysql -- --with-mysql-dir=/usr/local/mysql
If you’re on a PPC system, just replace `-arch i386` with `-arch ppc` and you should be good to go.
It’s been around two weeks now since I implemented a technique suggested by Sean Sperte and I have to say it’s working brilliantly. I’ve gone from around a hundred (on most days) spam messages passing through my mailbox down to zero. Zero. Nada. Zip. Zilch.
Gmail has worked almost flawlessly at catching spam and forwarding legitimate messages with only 2 or 3 false-positives, none of which were urgent messages, so if you’re looking for a fairly simple solution to battling spam, I suggest you go read Sean’s blog entry.
I’m not quite done with Subversion yet and have a few more tutorial-type entries planned over the next while provided the day-to-day comings and goings don’t get too much in the way along with finally getting an article I’ve been very, very slowly chipping away at (sorry Caroline!) for the last few months out the door and onto the editor’s desk.
That said, today I want to cover a simple nicety you can add to your Subversion install allowing you to more easily stay on top of incoming changes. This is particularly useful when more than one person has commit access to a project.
Monitor Subversion commits via RSS
Today we’re going to generate RSS output of changes being committed to Subversion. As usual, you’ll need your web browser, a text editor such as TextMate, and a Terminal window.
Getting Our Tools Together
To accomplish our goal of having an RSS or Atom-formatted XML file of repository changes output, the first thing we need to do is grab a copy of svn2feed.py, a hook script that will do the heavy lifting for us.
You can download svn2feed.py here (Right or Control-click and choose “Download Linked File” from the contextual menu).
Now that you have the file downloaded to your Desktop, using the Terminal, copy (or move) the file to the “hooks” directory in your repository. Using the example from the previoustutorials, let’s assume that is /usr/local/svn/.
Note that there’s a “hooks” directory in each versioned project, but also a global one for the repository itself which is the one we’re interested in.
Next, change the file permissions on the script to ensure it is executable.
sudo chmod ugo+x
/usr/local/svn/hooks/svn2feed.py
Our script to do most of the work is now in place. Next we need to create a post-commit script which will be executed - you guessed it, after a user commits a change to Subversion.
Automating RSS
In this case, we’re only interested in generating a feed for one project in the repository. Using our previous example, let’s create a new file called post-commit in /usr/local/svn/metropolis_blog/hooks/ and open it in your preferred text editor.
Take the contents below and copy/paste it into your post-commit file.
You can see the full documentation for what each of these items do in the svn2feed.py script, but the gist of it is that we’re telling the script to execute svn2feed.py using Python (which is installed by default on Mac OS X), keep the last 100 entries, use the Atom format, set the revision number based on the commit, set a permalink using the item-url, the full address of the feed itself via http, and where to actually save the XML file that gets output.
The REPOS variable is the path to your project in the repository.
Save the changes and close the file. We’re almost done.
Creating The Output Directory
Lastly, create the rss directory on your web server (eg. in /Library/WebServer/Documents) and make sure it is writeable by the script.
You’re now ready and can easily verify that everything is functioning by committing a change to the repository. If no XML file is output, odds are that the permissions are not set correctly. Assuming everything works as it should, simply subscribe to your RSS or ATOM feed and enjoy!
Before I forget, you might want to make sure Apache is running prior to attempting to subscribe to the feed ;-)
In the earlier post we ran the svnserve daemon manually. While this is fine as a one-off event, if you ever need to restart your system, we shouldn’t have to worry about remembering to start the process manually. Instead you’ll want to automate it. Thanks to the powerful launch facilities built into Mac OS X, this is a simple process and I’ll make it even easier for you.
The preferred way of launching background processes in Mac OS X means using launchd by creating LaunchDaemons and LaunchAgents which are simple plist (Property List) files which instruct launchd on how to start or stop these processes. The important difference in the two is that LaunchDaemons are intended for processes which should remain running even with no users logged into the system; perfect for Subversion.
Download this LaunchDaemon plist file and copy it to the LaunchDaemons folder in the Library folder on your system. Open the file in your preferred text editor and look at line 16. If you followed the earlier post on setting up Subversion, then you don’t need to do anything. If you created your repository in another location, you’ll need to edit the path to the repository on that line. When you’re done, save the file.
We’re now ready to make sure it will work. If you’ve got the svnserve daemon running, open up the Activity Monitor and locate the svnserve process. Select it and press the Quit Process button in the Activity Monitor toolbar. You should be asked for your administrator password. When the process exits it will disappear from the list.
After the process has closed, switch back to the Terminal. We’re ready to test our LaunchDaemon to start it up again. In the Terminal, type the following:
Enter your administrator password. You should be returned to a new prompt in the shell if everything goes well.
To verify that our process is registered with launchd, we can print out a list of all the processes run with launchctl by running:
sudo launchctl list
You should see the org.tigris.Subversion item in the list. You can further test that the LaunchDaemon works by simply restarting your system and again checking the Activity Monitor to verify that the svnserve process is running.
Source control is something thought to be geared more towards developers and those doing more traditional computer science-type programming, especially when working in a team environment. Source control is also an invaluable tool for web designers and developers alike.
Source control comes in many flavours — the two most popular and widely used systems being CVS (Concurrent Versions System) and Subversion, a successor to CVS which significantly improves on the major gripes most people have with the CVS source control system.
The problem with both is mostly from the aspect of approachability. Once you get the hang of them, it becomes natural and there will be times when you wonder how you ever survived without it, but until then, using, and more so, setting up your own source control system is a daunting task.
First steps: pick one. Your best bet is Subversion as it has been gaining in popularity and is under active development in the open-source world. Ask anyone doing serious development in Ruby on Rails for example and I’d bet 10 out of 10 times they’ll say they’re using Subversion.
If you’re a lucky developer working on Mac OS X, getting up and running with Subversion is trivial provided you have a handle on a few basic Unix commands. In this mini tutorial, I’ll walk you through installing Subversion, creating a new repository and importing a project. Ready to get started?
Step 1: Installing Subversion
We can cheat here and go the quick route using an installer package created by Martin Ott of The Coding Monkeys, the fine folks behind SubEthaEdit. Once you’ve downloaded and un-zipped the .pkg installer file, double-click the installer and run through the setup screens. Subversion will be installed into /usr/local which is where you want it since it won’t mess with anything in the core Mac OS X install.
The Subversion binaries are installed in /usr/local/bin. Of interest are svn, svnadmin and svnserve. The first two are your administrative tools for interacting with Subversion, the the svnserve binary (application) will allow you to run your own Subversion server that you can work from.
At this point you should have Subversion installed.
Step 2: Customize Your $PATH
To make working in the Terminal easier, we should tell your shell of choice (typically Bash), where to look for executable programs such as the Subversion binaries. To do this, you need to create a file in your home directory (eg. /Users/your-user-name named one of bash_login, bash_profile or bashrc.
In order for the file to be recognized by the shell as a configuration file it needs to be saved with a period (.) at the beginning of the file name. To create the file, open up your text editor (TextMate or BBEdit will do fine) and add the following:
When you’re done, save the file. Remember to prefix the file name with a period: .bash_profile, for example. You’ll need to open a new Terminal window for the change to be loaded. You can test that things are working by typing sv and press Tab. If the name auto-completes, you’re good to go.
Step 3: Setting Up A Repository
We’re now ready to create a new repository. This is where our files will be stored. This is not where we directly interact with and modify files though, but where data is pulled from and committed to when we make changes. If it’s not all clear, it hopefully will be shortly.
Open a new Terminal window (you can find the Terminal application in the Applications/Utilities folder on your computer). Type the following command:
sudo mkdir -p /usr/local/svn
This will create a new folder named ‘svn’ in /usr/local after you’ve entered your administrative password which you will be asked for. This will be our Subversion repository. If you’d rather use a different location, feel free to change the path. For example, an external drive or in your Home directory.
Assuming you followed the above, you’ll need to change the group ownership on the ‘svn’ directory in order to be able to write to it. To do this, type the following at a new prompt in the Terminal:
sudo chgrp -R admin /usr/local/svn
This changes the group associated with the main folder and recursively down into the folder to the admin group in Mac OS X. As long as you belong to that group, then you should be able to write to that folder.
Step 4: Create a New Project in Subversion
We’re now ready to create our first project in Subversion. This will get us our initial setup from which to work from. As an example, let’s say we’re creating a new blog for a client named “Metropolis & Co.”. We might name the project metropolis_blog. To create the new project, back in the Terminal, enter the following:
If all is successful, you should be returned to a new prompt in the Terminal.
Step 5: Securing Our Project
The next thing you might want to do is secure access to your project, especially if you’re working in a team environment with different people on different machines or in different places. There’s a bunch of different things you could do here and I’m going to keep it simple for now. Just the basics — controlling read/write access and adding usernames and passwords.
In order for multiple people to interact with your new Subversion repository, you need to run svnserve on the system you ran through the previous steps on. So, before we start up the server, we need to configure the access details which can be done on a per-project level. So in our case, we want to edit the settings for our ‘metropolis_blog’ project.
In the Terminal, switch to the project directory by going to:
cd /usr/local/svn/metropolis_blog
In that folder you should find a series of directories and files. Right now we’re only interested in the conf directory’s contents.
cd conf
or
cd /usr/local/svn/metropolis_blog/conf
In the conf folder you will find three files: authz, passwd and svnserve.conf. We won’t look at the authz file now, and instead start by editing the passwd file:
sudo pico svnserve.conf
You can read through the usage notes in the file, but the basics of what we want to do here is enable read-only access anonymously and make write-access require a username/password which we will specify next. To do this simply change the matching lines in the svnserve.conf file by removing the preceding hash mark (thereby uncommenting the lines).
If you wanted, you could create a new password file in a different location and point to it in the file, but in this case, we’ll just use the defaults. Save the file by pressing Control-O and then Control-X to quit the pico editor. If you have TextMate installed you could alternatively edit these files with it.
Next, let’s create two user accounts for which we’ll grant write access to the repository. In the Terminal, type:
sudo pico passwd
Using the examples already present in the passwd file, add a couple new username/password combinations. For example:
user1 = password1
user2 = password2
These are obviously crummy account credentials. I trust you to come up with something a bit tougher to figure out. When you’re done, press Control-O and then Control-X to save and quit.
We’re now ready to start up our Subversion server and import some files into our project.
Step 6: Start the Subversion Server Daemon
Starting the background daemon process for Subversion built-in server is as simple as running:
Here we’re telling the daemon to run as the root user on the system, run as a daemon (background process) and use our repository (the —root here indicates the root of the repository, not the root user in Mac OS X which is simply implied by executing the command with sudo).
If you check in the Activity Monitor application on Mac OS X, you should see the svnserve process listed. If so, you’re set to go to the next step.
Step 7: Importing Files into our Project
Now let’s create a fictitious project structure which we can import into our project. On your Desktop, create a new folder called import. Inside that folder create three subdirectories named trunk, branches and tags. We’ll use this as the base for our import.
Once those folders have all been created, in the Terminal, type:
Assuming all goes well, you should see some output in the Terminal indicating that your folders were added along with a revision number. Now is where the fun starts. Now we need to test that we actually, really did commit something to Subversion.
Step 8: Sanity Check
To verify that we did in fact commit something into our repository, the best way to do a sanity check is to check it back out somewhere. So let’s do that, make a quick change and commit the change back to Subversion.
To check out your project into a working directory (often called a ‘sandbox’), do the following in the Terminal:
svn co svn://localhost/metropolis_blog ~/Desktop/my_checkout
This should checkout the contents of the project into a new folder called my_checkout on the Desktop. If it worked you should see a nice confirmation message in the Terminal and find a new folder on your Desktop named my_checkout with the previously imported folders inside. Cool, eh?
Now we want to create a new file, add it to our repository and then commit the file into the repository. You can add and remove files to your hearts content with Subversion, but until you commit the changes you don’t actually affect the repository, only your local working sandbox.
So create a new file in your favourite text editor. In this case, let’s create a file called readme.txt inside the trunk subfolder. Now back in the Terminal we’re going to add the file and then commit it to Subversion (press Return after each line).
As usual, Subversion should provide you with some feedback indicating whether your new file was added or not. If so, you’ll see a new revision number. At this point you’ve got a nice little development environment setup for source control for your projects. And now that we’ve done our sanity check, you can safely delete the import folder you started with.
If this was helpful or if you have any comments or corrections, please feel free to leave them. I do have another small piece to add to this tutorial but which will be included separately in the next day or so.
*Updated on March 4, 2007 to add details for customizing your $PATH variable in the Terminal.
It’s amazing the little things you can learn when you RTFM. Like the other day when I came across mention of a new command in the RubyGems gem program (version 0.91 or newer) which makes it easy to check against a remote repository to see if your installed gems are up-to-date.
The command is straightforward: sudo gem outdated
You’ll get a nicely output list of your outdated installed gems showing the current version followed by the most recent version number. The usual gem update procedures apply from there. Happy updating!
I can’t recall where I saw this tip, but for the sake of propagating it across the interweb, I’m going repeat it.
To give DiskWarrior a swift kick in the pants when booting your machine and during general operation of the application, make yourself a backup copy of the original DiskWarrior CD on DVD instead. Simply pop the disc into your Mac, launch Disk Utility and create a new disk image of the DiskWarrior CD on your Desktop. Burn to DVD media. Done.
Alternatively, use Toast to accomplish the same thing.
Internet Explorer 6 has a lot of “quirks”. Some might call them bugs. Some might trade their soul for all users of said browser to give it up and just move to Firefox, skipping the just-released IE7 entirely. The web design community at large might get to keep more of their hair on their heads if that were the case. Sadly, not much chance of that.
One “bug” is an annoying flickering problem when images are specified as a background on links. The fix has been around for some time but I’ve seen very little mention of it anywhere. I came across it a few weeks back and finally had an opportunity to try it out in a real-world test. And guess what? It bloody well works!
So, here’s what you need to do.
In your site/app/blog/whatever — either encapsulate the bit of code below as a piece of inline Javascript or drop it into a linked JS file and you’re all set. No need to worry about onload handlers and the like. It just works.
Back in early May I talked about what I dubbed ‘Sliding Door Buttons’. I’ve continued to evolve this technique to the point where it’s now behaving consistently across browsers and platforms.
Sliding Door buttons example preview
The essence of the technique and the reasons behind its usefulness remain the same, but there are now some additional enhancements that I think add to the implementation and provide basic design features that might otherwise be difficult to achieve using other methods.
Code Structure
The HTML code required is slightly rearranged and helps work around some basic problems in the previous implementation. But before we talk about any specific changes to the CSS, let’s look at the basic structure of a sliding door button.
<div class="buttons">
<a href="#" title="Add a new user" class="btn"><span>Add User</span></a>
</div>
<div class="buttons">
<a href="#" title="Cancel" class="btn-disabled"><span>Cancel</span></a>
</div>
The surrounding div element with the class “buttons” is not necessary, it’s simply included as part of this illustration. The basic code is an anchor with a span element inside it. Simple? Yes. Clean. Yes. Do we have the hooks we need to style it? Yes.
The only real difference between this version and the previous one is that I’ve reversed the order of the span and anchor and which element has the button class applied to it.
The CSS
As mentioned in the first part, the basic idea behind these buttons builds on Doug Bowman’s Sliding Doors of CSS technique but rather than being focused on site navigation, we’re instead focusing on a common UI element, the button. The approach is essentially the same: use simple HTML elements, two images (one for the left side and another for the right) and allow the button to expand as necessary to accommodate longer text.
The big change that helps resolve the consistency problem in the earlier implementation turned out to be very simple: use display: table-cell on the anchor element. For Windows IE, note that you’ll have to use display: inline-block since it’s the only browser to really support it (so far). You can do that simply with a conditional comment.
Following the example here, we could create as many variants as necessary with fairly minimal additions to the CSS code. To take it one step further, you could also add an inline image inside the space to add a simple icon to the button.
How To Create Disabled Buttons
The one real missing piece of the puzzle in terms of making the behaviour closer to a traditional input button is that we have no real way of disabling the button. It’s a link. It’ll always be a link. What we can do is use a bit of JavaScript magic to swap our sliding door button with a nulled button. In this case for the nulled button we remove the anchor and replace it with another span element (another inline element in HTML).
Here’s a quick example of this technique in action. I’m not demonstrating the JS swapping here. My suggestion there would be to look at Prototype for that sort of interactivity since it makes it very easy.
As before, I welcome your questions, comments and critiques. Simply drop a note in the comments.
In setting up the launching pad for what I suppose will be my second endeavour in the “Web 2.0” application market following the initial beta launch of FiveRuns which went live last week, I quickly transformed the static “coming soon” page for remarkr into a simple Rails application to handle beta/information signups.
Local development with Rails is simple using either the default Webrick server or mongrel, but moving the application to my web-host of choice, Dreamhost proved to be a bit frustrating. It all worked in the end, but was made tedious by some wonky documentation. In the hopes of saving someone else the same trouble I ran into, here’s some additional notes on getting your Rails app running at Dreamhost.
Assumptions
I’m assuming you’ll be running the application from the web-root, meaning the main page of your app would be displayed if the user went to www.yourdomainname.com, and not app.yourdomainname.com.
Baby Steps
Before you do anything, be sure to create a database instance to use for your domain. Make a note of the address, username and password as you’ll want that information for the database.yml configuration file which should go under production.
You’re ready to upload your app via FTP. Dreamhost apparently requires most of the directories for your Rails app to have 766 permissions for folders and 664 for most files, the exceptions being your public directory and the log directory which can be set to 755. If you are getting weird errors and things aren’t running as expected, this is something to check.
Configuration
In your config/environment.rb file, be sure to uncomment line 5 to set the ENV['RAILS_ENV'] variable to ensure your app runs in Production mode.
ENV['RAILS_ENV'] = 'production'
While you’re at it, you may also want to store sessions in the database, and if so, uncomment line 28.
If you are planning sending e-mail from your Rails app, you’ll need to set some defaults for ActionMailer as Dreamhost requires you to use smtp and to authenticate to the mail server in order to send mail. I recommend reading the mailers examples on the Rails Wiki.
Lastly, in order for URLs to be redirected properly, you may (this may be deprecated with Rails 1.1.2 and newer) need to add one last line to the end of the environment.rb configuration file. If so, it should look like this:
# Extra configuration to fix Dreamhost Routing problems
# Make sure to also uncomment the ENV variable (see line 5) above to set
ActionController::AbstractRequest.relative_url_root = "/appname"
Dreamhost Web Admin Configuration
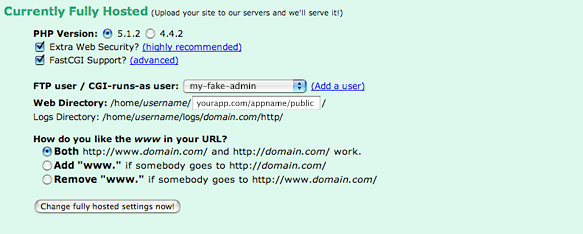
Now you’re ready to make a small adjustment to the default domain setup. Essentially rather than leaving the Web Directory at “/”, we need to tell it to use the public directory for our app.
Dreamhost domain setup for Rails applications
So, if your application was called addressbook, your Web Directory would be domain.com/addressbook/public. Simple right? While you’re at it, make sure you have the Fast-CGI checkbox checked.
Dispatch!
The last thing we need to adjust how the application is dispatched which means two more small adjustments.
Open up the .htaccess file in public and set the default redirect rule for dispatching Rails to use the fcgi script. Change line 28 to read:
RewriteRule ^(.*)$ dispatch.fcgi [QSA,L]
The last is changing the shebang line in dispatch.fcgi which you can find in the public directory of your application. For Dreamhost, it should be set to:
#!/usr/bin/env ruby
This will locate ruby and should generally work even in your development environment.
That’s it. Assuming all went well you should have a Ruby on Rails application up and running on Dreamhost.
One of the small tasks I set for myself in working on an upcoming web application project was to construct any buttons required in the app using simple anchors rather than using either input or button elements, handling the visual appearance with CSS.
This was a challenging task in some respects due to some cross-browser quirks (what else is new?) and the simple desire to not create excessive code for the sake of nice buttons.
In the end, a smattering of ALA technique and home-brewed trial and error did the trick and allowed a fairly robust and flexible system for constructing buttons while aiding accessibility and ideally making users with screenreaders happy as well.
The main designer/developer benefit is that these buttons are easy to style, can be easily repurposed to allow different styling and allow for translation into other languages without having to produce countless images. They also happen to work based on my testing in IE6/Win, Safari and Firefox. I haven’t done any testing in Opera, but I suspect that they should be fine in newer versions of that browser as well.
Cutting Up Your Buttons
Since this technique is based on Doug Bowman’s Sliding Doors technique , I suggest you give it a brush-up read if necessary. It lays the overall foundation for the sliding door buttons technique.
An example of Sliding door buttons with CSS
The short version is this: we need two images. A left side and a right side. The left side will occupy the space from the left edge of the button text to the left edge of the button background itself. You should get the general idea from the screenshot above.
One key thing to remember is to make the background of the button on the right side wider than you need. The reason for this is to allow the button to expand and contract with the length of the button text and to allow a certain amount of font scaling.
Mark Me Up
The basic markup is as simple as it gets. You need an anchor and a span. It looks a little something like the sample below.
Simple, no? To style the button, you apply the left background image to the anchor and the right background to the span, remove the text-decoration from the links, add some padding to allow the entire button shape to be visible and set the span to display-inline.
The reason for placing the span inside the anchor is simple: doing it the other way around works fine until you get into IE and it all falls apart. Placing the span inside brings the added benefit of ensuring the entire button shape will be clickable by the user.
As part of a project I’m in the midst of, I needed to be able to take an array which may have one or more keys with empty values and remove those elements from the array in order to find it’s true length. In this case, I didn’t care about the actual data in the array, just the count() value returned.
After searching through the PHP documentation, I didn’t see any internal functions or methods that would do exactly what I needed, so out to Google I went and after a bit of searching, refining my query and testing, I found the solution which I thought I would share — if nothing else, because I hope it makes it easier for others to find.
The code looks like this:
// @param $a = array passed into the function
// @param $b = result returned
function array_trim($a) {
$j = 0;
for($i = 0; $i < count($a); $i++) {
if($a[$i] != "") {
$b[$j++] = $a[$i];
}
}
return $b;
}
$b = array_trim($my-array-to-trim);
Simply create a variable, and then pass your array to be trimmed through the function. It takes care of the rest and will output a nicely compressed array of key/value pairs. The empty key/value pairs are removed whether they are at the start, middle or end of the array.
Of course, if there’s a better way, I’m open to suggestions!
Running your own local server for web development is a great thing whether it be Apache, “Lightty”: lighttpd or something else. It makes it possible to develop and test under similar conditions to a deployment environment (unless of course you’re developing for a large-scale deployment across multiple load-balanced servers and such).
As I’ve said before, Mac OS X shines in these type of situations because of the flexibility of its Unix underpinnings. You can compile and run Unix-oriented application as well as nice-looking GUI apps alongside Java, Perl, Ruby, PHP and more. And since the beginning, Mac OS X has come bundled with the Apache web server for hosting your own sites.
So. Let’s take stock of what we need to get a reasonable framework running for managing development environments with Apache, Virtual Hosts and a good old-fashioned DHCP.
Mac OS X (or some flavour of Windows if you really must).
Apache web server (for this example, but the concept should work for any reasonable web server).
“Web Sharing” enabled via the Sharing Preferences in Mac OS X.
Dynamic DNS account and client software. Various options are available, but we’ll look at using DynDNS’s services in this case.
Custom domain name or choose from one of the free dynamic hostname options.
Getting Your Domain Name
There’s two ways to deal with this — register a domain via your usual registrar and point it to the appropriate DNS service or register the domain with DynDNS. If you plan on using one of their free options, you just need to register for an account to get started. For the sake of this tutorial, let’s assume you’re using their Zone Level services and a custom domain name.
Create an account at DynDNS and go to the “My Services” section.
If you haven’t done so already, register a domain name. Once complete, it should appear under Domain Registration as well as under the My Zones section. You should see an indicator for “Custom DNS”. A subdomain of one of their stock domains will appear under the My Hosts section instead.
In the My Zones section, click on the “Custom DNS” link in the table. This will display your Custom DNS settings including your Hosts (A) records, Alias (CNAME) records, MX records, etc. This is where you can add however many custom subdomains you need.
To add a new Host, click on the “Add New Host” link above the listing of your Host records.
Enter the host you wish to use. For example: subdomain.
For host type, you can leave it at the default which should be dynamic unless you happen to have a static IP address, which unless you’re running off a business-grade internet connection, you probably don’t have.
Your current IP address should be detected automagically.
Click the Add Host button and you’re done.
The Dynamic DNS Client
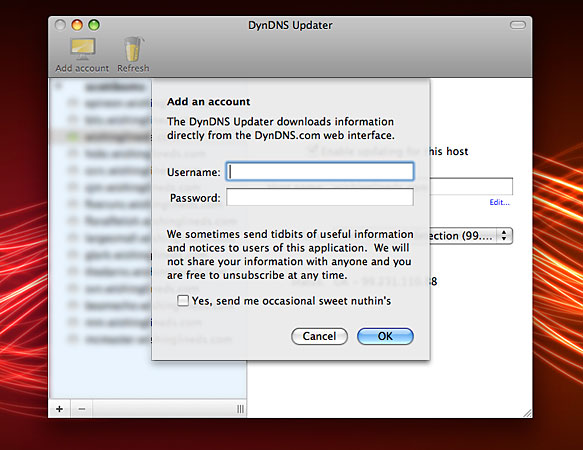
The next thing on the list is to grab a copy of the Dynamic DNS client software. In our case, we’re going to use the official DynDNS Update software which is easier to use and requires less configuration than the alternative client options.
To setup the DynDNS Update software, install it on your system and launch the application.
Click on the Add button to enter your DynDNS account credentials. This is the same information as the DynDNS account you created earlier. Assuming your account info is accepted, any existing DNS addresses will be refreshed within the client.
You will be asked to install the DynDNS daemon which is the background process that will run on your system and update the DynDNS service when your IP address changes.
Click on a host in the sidebar list. The details of the host will appear on the right side of the window. Click the “Enable updating for this host” in order to keep a particular hostname updated.
Adjust the interface option as needed. Typically this should be set to “Web-based IP detection” if you wish to be able to access your system remotely (or to allow others to access your dev environment by name rather than IP).
DynDNS client software for Mac OS X
When you’re done, press the Add button to continue. Back in the main window, click on the Active checkbox for your domain. If the host is found it should return “Ok” and everything is ready to go. Next up — Apache.
Setting Up Apache
Although Apache’s configuration file is long and perhaps a bit drawn out for many, it’s still reasonably easy to read and understand and creating VirtualHosts is not difficult. My personal preference is to keep VirtualHosts separate from the main httpd.conf file for numerous reasons including OS upgrades, cleanliness and ease of management.
The structure I prefer is simple. Create a new folder in /etc/httpd/ called hosts. This is where we will keep our individual VirtualHost settings. One file for each domain. Next, open up the httpd.conf file in your favourite text editor and scroll way down to the end of the file. You should see a section that contains the Include directive.
# script as well as its and *.html, *.css etc. files.
<Directory /Library/WebServer/Documents/validator/htdocs>
Options ExecCGI FollowSymLinks IncldesNOEXEC Indexes MultiViews
AllowOverride None
AddHandler server-parsed .html
AddCharset utf-8
</Directory>
# Tell httpd that "check" is a CGI script
<Location "/validator/htdocs/check">
SetHandler cgi-script
</Location>
Include /private/etc/httpd/users/*.conf
# Include configuration files for VirtualHosts
Include /private/etc/httpd/hosts/*.conf
That first line includes the necessary setup to allow each user account in OS X to have their own Sites folder where they can host their web site. We’re going to follow the same methodology with our hosts folder as shown on line 1223 in the screenshot above.
Now that we have Apache set to include all files named with a .conf extension, we can go about setting up our first VirtualHost configuration.
NameVirtualHost *
<VirtualHost *>
ServerName subdomain.mydomain.com
DocumentRoot /Library/WebServer/Documents/subdomain
RewriteEngine On
<Directory /Library/WebServer/Documents/subdomain>
Options -Indexes ExecCGI FollowSymLinks
AllowOverride None
Allow from all
Order allow,deny
</Directory>
</VirtualHost>
Change the settings you wish to use for the VirtualHost as needed. Copy files in to the appropriate directory for the host and you should be up and running in no-time flat. Questions, comments?
The browser cache is both our friend and our enemy. As web designers and/or developers the cache is our friend because it’s useful for making sites render faster and therefore seem more responsive to the end user, but it’s our enemy because can wreak havoc when changes to a CSS file are made and the browser doesn’t want to let go of the old, cached version.
It’s a pain to have to clear your cache all the time to make sure changes are working as expected during development as well as after deployment to a live environment. Thankfully there is a nice, simple solution aside from sending no-cache headers, which I’ve found don’t always work. I’ve used it myself on a number ofoccasions and have seen it used elsewhere.
So what is it you ask?
Simply add a post-style variable parameter to the end of the link to your stylesheet(s). I like to use a version numbering type scheme myself. Something like www.yoursite.com/css/main.css?v=1.000. This keeps the browser from caching the CSS file, ensuring that the browser is grabbing the right version without having to clear caches and restart browsers.
In the last few months I’ve had the opportunity to explore the Flickrpublic APIs using Dan Coulter’s phpFlickr wrapper classes to handle the API calls and database caching to speed things up.
Although the Flickr APIs are constantly evolving, the phpFlickr classes have pretty much kept up with that evolution and made it very easy to search, view and manage your photos and photosets. As a web developer this is pretty handy because it means there’s another option for creating photo galleries or special applications without having to reinvent the wheel in terms of managing photos or managing multiple photo galleries with different content.
Just about everyone I know who’s seen Flickr thinks it’s great, so why not make the most of what it can do for you?
Getting Started/Installation
The phpFlickr classes are simple to use. Start by downloading the latest version and sign-up for a Flickr Developer API key. You’ll need to the API key to interact with the Flickr APIs and it’s helpful for them to understand how the APIs are being used.
Once you’ve download the phpFlickr package, you’ll need to un-tar the file and upload it to your web server (or drop it into your development environment). That’s it for installation, you’re now ready to start working with the classes.
Searching
The example we’ll use to get you started in using the class will be simple: find a set of photos based on a particular tag. Here’s the entirety of the code. I’ll explain it in a moment.
Save the code into a new file named search.php into the phpFlickr directory on your web server or in your test environment and test accessing the file in a browser. You should have a number of images returned if your query found anything that matched.
The basics of what the code does is simple, so let’s look at it line by line.
Line 2: Include the phpFlickr classes. This needs to be called before the page content loads.
Line 3: Create a new instance of phpFlickr using your API key.
Line 5: Provide a $tag variable to search by. This can be any literal string.
Line 6: Provide a $num variable to tell the script how many results to return (up to 500).
Line 7: Provide a $username to tell the script whose photos to search. This is the full nickname of the user.
Line 8: Setup a counter variable to iterate through the results.
Line 9: Create an $nsid variable which will hold the NSID of the Flickr user based on their $username.
Line 10: Get the chosen user’s base photo URL.
Line 11: Execute the API call based on the above parameters.
Line 12: Although commented out, this would display the contents of the data array returned from Flickr.
Line 13: Start displaying the results.
Line 14: Print an error if no results are returned.
Line 17: Loop through the results if multiple photos are returned and print out a link to view the photo on Flickr
Line 18: Display the Medium sized photo. Other options are “Square”, “Large” and “Original”.
Line 19: Add 1 to the counter variable’s current value.
Hopefully this, along with the other examples available will give you a start at using the Flickr API.
Normally OS upgrades seem to go so smoothly… But this one left me (and I’m sure many others) with a nasty surprise — no communication between PHP and MySQL. Not nice. After a couple quick searches and no answers I decided to search out one myself. Discovering the problem was simple, and so apparently, was devising a solution.
If you fire up a quick PHP info file, you’ll see that the MySQL socket specified in the included version of PHP is wrong (or at least different and not what is expected) compared to older OS releases.
In 10.4.4, it is set as with-mysql-sock=/var/mysql/mysql.sock, whereas previously it was /tmp/mysql.sock.
Thankfully, there are at least two things you can do to remedy this.
Locate and edit a php.ini file (by default it should be in the /etc directory and find the mysql.default_socket line and simply add /tmp/mysql.sock following the equals sign, save and restart Apache.
In a plain text editor, create a new file in /etc/ named my.cnf. In the file, include a line which reads (on two lines):
[mysqld]
socket=/tmp/mysql.sock
Edit: The original second solution has been removed due to security concerns as indicated by Apple. A revised alternative solution has been added in its place.
It’s been about two weeks since I posted the Livesearch functionality tutorial here and in the time I’ve been looking at the SQL query to see if there’s room for improvement.
I noticed that some of the results for certain queries didn’t make sense. What I realized I had forgotten was that it’s raw, Markdown formatted text stored in the database tables and the results reflect all positive matches to the string a user submits through the feature. This includes matching bits of URL strings…
In effect what I thought was wrong, wasn’t. It was a matter of false expectations of what the results should be, that they weren’t as good as they should be or that I had made a mistake with the query. The query correctly checks against the entry_textentry_title fields. Taking this a step further, we could add MySQL’s full-text search to make searching even more robust.
Another small catch to keep in mind is that searches are case-insensitive meaning that a search for “Apple” should yield the same results as “apple”.
The point I’m trying to make here is simply that you should look closely at the results to ensure that everything is working as you expect. Test a handful of queries using the command line or some other database management tool.
Other Examples Of Using XMLHTTPRequest
This XMLHTTPRequest thing is really starting to take off now that newer browsers are supporting the feature more consistently and that the web community has started to take notice.
As a result you’ll likely see the Livesearch functionality cropping up on more and more blogs/websites in the near future and in more innovative and creative ways. Two other excellent examples of the XMLHTTPRequest object can be found over at map.search.ch and of course Google Suggest.
Since I slipped up yesterday and inadvertently posted an entry destined for my ‘Hits, No Misses…’ links blog on the main blog I encountered the problem of a small blip in the sequential numbering of my entry IDs. Thankfully this is fairly easy to correct and stuck me as a good little mini-tutorial for anyone who may not know how to do this.
Using my own situation as an example let’s say you just posted an entry to your blog and it is recorded in the database as mt_entry number 439. You then notice you posted it to the wrong blog. Oops.
MT Entries table statistics in MySQL
To remedy the situation you re-post the entry to the correct blog (this is easy with ecto) which then leaves you with two entries. Next you delete the first entry (the one posted to the wrong blog) leaving the second entry with an ID of 440.
If you were to look at the mt_entry table for your Movable Type install using something like phpMyAdmin you’d notice the last two entries were now 438 and 440 and the next autoindex value would be 441. Clearly there’s a blip in the system, but it’s an easy fix.
Un-Blipping The System
To get things back to normal you’ll need to have access to your MySQL database through the command line or something like phpMyAdmin. Start by looking at the mt_entry table. Note the last entry ID (based on the example, this will be 440) and change the ID to the missing ID. In this case it would be 439.
Now that the IDs are back in sequential order there’s still the matter of the autoindex value which, if left alone, will result in the next new entry to have an ID of 441. In order to fix this, we have to reset the autoindex value so the next ID will be 440 instead of 441. To do this, simply execute this query on the me_entry table:
ALTER TABLE mt_entry AUTO_INCREMENT=1
You can now safely rebuild your indexes and archives to see the changes reflected in your site.
Alternatively, you can probably avoid at least part of this procedure by not double-posting the entry to two different blogs and simply change the entry_blog_id value and rebuild. Note to self for next time this happens…
It’s been a while since I’ve done a tutorial on anything so as a last-minute holiday treat I’ve got one cooked up on a feature that I’ve wanted to explore implementing here for some time.
Resources
Let’s get the resources out of the way so you know where to get the relevant pieces of open-source code and can see a nice implementation of what we’re going to build.
Garrett Murray: Maniacal Rage — For doing a nice implementation of this with a couple of extra features than those than come out of the box and which I have attempted to appropriate into my own version. Cheers, mate!
Laying The Groundwork
Follow along and you should have a basic framework for implementing livesearch functionality on your own site. Start by downloading the required BitFlux JavaScript file and take note of the installation details. We’ll go over them here, but read through the content on the topic there first.
Take the ‘livesearch.js’ file and copy it to your site wherever you keep your Javascript files. For the purposes of this tutorial, I’ll assume this file will be located in the root directory of your site.
In the livesearch.js file locate the first line that contains /livesearch.php?q= near the end of the file. To specify the search variable as something other than “q”, change this here and in the lines that follow. There are a total of three instances that will need to be changed.
As an example, to rename the variable to “s”, the replacement text would be /livesearch.php?s=. Also note that you can rename the livesearch.php file to something else if desired. This script will do the work of performing the search and returning the results back to the browser. Just be sure to make the same changes in the Javascript if you rename the file.
Determine the necessary SQL query to search your Movable Type entries. Exactly how you decide to do this is really up to you. The SQL here is more of a quick example and you may want something more robust.
SELECT entry_id, entry_title, entry_excerpt,
DATE_FORM(entry_created_on, '%Y_%m') AS date
FROM mt_entry WHERE entry_text LIKE '%$s%'
ORDER BY entry_created_on DESC
The $search variable included in the SQL should also match the name passed from the search form. Exactly what is returned is entirely up to you. In this case, the query returns the entry ID, title, and excerpt with the results sorted by date in descending order.
To restrict the results to a single blog if you have more than one, you would also want to filter by the entry_blog_id in the WHERE clause. For example, WHERE entry_blog_id = '1' AND entry_text LIKE '%$s%', etc.
It would be useful to split the results into multiple pages if a large result set is sent back (eg. 10 results at a time) but that’s outside the scope of this tutorial.
The next piece of the puzzle is to return the results in a standard XML format to be parsed by the XMLHTTPRequest JavaScript object. The Wiki page describes the format required but you can see it more clearly here in context of the PHP you will need to return a correctly formatted result set.
You may not want to copy this verbatim, but it should be enough to give you a good start on how to return the results. Include links and such where appropriate and watch out for whitespace parsing and validation issues with the XML returned. Note that you don’t have to use an unordered list here, this is just a suggestion to keep thing clean and arguably semantically correct. It’s also easy to style with CSS.
Once your PHP script is completed, test it manually to see if it’s returning results as expected. Upload the file to your server and call it along with the appropriate search query appended. For example,
yoursite.com/livesearch.php?s=querystring
If all goes well and matches are returned you should see a nicely formatted list of results. If not, you’ve got some SQL or PHP debugging to do.
Implementation
Implementing livesearch into Movable Type, replacing the default search functionality is straightforward, but presents a few challenges. The first thing to take into account is where search is located throughout the site. For now, I’m assuming that search functionality is only available within the Main Index template.
In that Main Index template, locate the search form code. The default search form in Movable Type does not include an ID/name attribute and uses a button we technically will no longer need. Change the form code to:
Formatting is important here. Make sure the third line with the DIVs has any whitespace removed. Whitespace appeared to cause problems returning results during my testing.
Next, in the HEAD section of the template, include the livesearch.js file and initialize the livesearch script by attaching an onload event to the BODY tag.
<body onload="liveSearchInit();">
There are better ways to handle this, especially if you need to be able to execute multiple functions on the DOM when the page loads, but this is suitable for this simple example. Save the template changes and style as desired with CSS. Repeat as required wherever the search form appears.
Caveats
This isn’t foolproof of course. It doesn’t work in some browsers, or in some cases, not completely. It doesn’t work at all in IE 5 for the Mac or Opera 7.x (and one can assume earlier versions as well). It mostly works in OmniWeb 5.1 beta 5 based on very minimal testing. And there’s also the issue of graceful degradation. Users with Javascript turned off are out of luck with search since livesearch relies entirely on Javascript. Providing a fallback for those users would be a worthwhile addition.
Sorry for the lack of posts over the last few days. I’ve been occupied with a small (large?) issue that I (accidentally) noticed and which seems to have occurred during the period back in October when I moved and upgraded the site to Movable Type 3.1.
During the process of the move and upgrade, I cleaned up the post IDs (kind of accidentally actually) and during one of the import processes, the actual entries for the blog got a bit messed up. In the body/summary fields, certain words somehow ended up capitalized wherever they appeared. Not coincidentally these words were all special reserved keywords in MySQL — such as DISTINCT, SELECT, DELETE, CHECK, FROM, UPDATE, etc.
I’m not sure how this happened and it’s been a real nuisance to fix, but it did provide me with an opportunity to update the archives to all use the Markdown with SmartyPants text formatting plug-ins along with cleaning up some of the less than semantically correct HTML throughout.
Overall things are generally better now, allowing me to get back to the next big feature (and the last) that will likely make an appearance after this weekend or early next week given my current holiday schedule; leaving me time to finish the design and architecture phase of a long-overdue redesign. This will also coincide with the even longer overdue launch of the Wishingline Design Studio, Inc. site.
I’ve said it before, but the right dose of inspiration hit and I’m on a bit of a roll with things so far. Hopefully I can keep up the pace for as long as I need to get it done.
Anyway, back to MT… The lesson here is: be very careful when you import or export your entries. I don’t know which method is better — using a MySQL dump or the built-in Movable Type export/import functions. One of those two produced the problem I ran into and I’m debating testing with a local MT install to figure out which one. If I do, I will post the results here.
Update
It appears that Movable Type was able to export/import the entries cleanly and also did not exhibit the problems I encountered with phpMyAdmin did.
One of the things we’re trying to accomplish with the big re-branding project I’m working on is facilitating global colour changes throughout the entire site via CSS (obviously). One of the items on the list causing problems is Opera’s handling of the input type=image element. Everything works as expected in older versions of the browser (as it does in every other browser out there, including IE5), but not the 7.x series which appears to contain a bug.
Implementation Details
The site currently (and going forward) uses a lot of image-based input objects (buttons) as opposed to the native OS-level widgets. These are also translated into around 40 locales — so there’s a lot to deal with. The newer buttons have been created as transparent GIFs using pixel font type. The idea is to apply a background colour and border to finish off the buttons with CSS.
Transparent image buttons
In Safari, IE, OmniWeb, Firefox, Camino and Mozilla applying a background-color property to an assigned class or ID on these input elements works as expected but in Opera 7.x this property appears to have no effect. I’m assuming part of this is related to that property is not necessarily appropriate for input objects, but every other browser seems to support it when the input type is set to ‘image’ so why doesn’t Opera (anymore)?
I took a look through some of the Opera docs and I’m not entirely sure what to make of things. For an experiment I tried creating a regular input element and styled the background. Of course it bloody well worked in Opera but failed in Safari. Very frustrating.
Up For Suggestions
While I continue to ponder this, does anyone have any ideas or pointers to articles or tips that might help? We’re looking at the feasibility of converting the inputs to plain vanilla images with links, but I’m not sure it will be possible given the use of a lot of complex Javascript. That, and the short timeline we have until launch.
Apple recently posted a great tutorial on their Developer Connection site on how to get the W3C HTML Validator running locally on Mac OS X. If you want or have a need for local access (particularly when offline) to the validator tool, I recommend following along and setting it up on your own systems.
The process involves checking out the project from CVS, updating a few files included in a provided disk image, editing your Apache configuration file, installing OpenSP and a number of required Perl modules and lastly a missing library in Mac OS X called libiconv.
Additional instructions, especially related to Perl can be found at David Wheeler’s site.
“This should be fairly easy and straightforward” I thought to myself when I first started looking at trying to do away with using MacCVSClient to manage collaborative CVS based projects. It bothers me because (a) it’s slow when dealing with large projects and (b) it uses a proprietary binary format for the CVS information files.
In the end it was a fairly simple procedure but I found myself running in circles trying to decipher information from various sources and turn it into something cohesive that was clear enough to a CVS newbie such as myself. Hence this tutorial, which will hopefully grace the Google archives for some time and save others the same frustrations I suffered trying to get this to work.
A Few Assumptions
Although this tutorial is intended for Mac OS X users, the majority of it applies to any Unix-based operating system which can run the bash shell (the default shell in Mac OS X). BBEdit is only available on the Mac though so that portion is of limited widespread appeal.
I’ve purposing left out things related to other shell environments to keep the article length down, but if anyone is stuck there and wants to know how to do this using other shells, drop a note in the comments and I’ll post some additional information or point you to where to get it.
Setup Your Environment
To save yourself some work you will want to set some environment variables to simplify interacting with the CVS binaries. To do this, fire up the Terminal application and type pico .bash_login to create a new file (or edit an existing one) in your home directory.
The first variable to set is CVSROOT which is used to indicate the location of your repository. Assuming you’re dealing with a CVS server running on a second machine and being authenticated using the pserver method, that variable would look like:
The second variable that you may need to set is CVS_CLIENT_PORT, though unless you need to use a port other than the default (2401), you can probably skip this step. If you are using a Firewall (hardware or software) make sure to allow traffic through this port.
export CVS_CLIENT_PORT=2401
The third variable is the CVS_PASSFILE which also is optional but useful if you want to store your unencrypted CVS password somewhere other than the default location in your home directory. Keep in mind that the pserver method sends data in plain text format so it’s possible that it could be read if intercepted by unauthorized parties — both your account information and the repository data itself. For details on improving this situation, see the Bonus Tip below.
The name of the file by default is .cvspass. The information for the CVS_PASSFILE variable should look like this:
export CVS_PASSFILE=~/.cvspass
The last variable we need to be concerned with setting is the CVS_EDITOR variable. Since we’re going to be using BBEdit for managing CVS, you can set this option to use the bbedit shell command instead of another CLI-based text editor such as vi or pico.
Save the changes to your .bash_login file by pressing Control-O to save the file. To apply the changes to your shell, either open a new Terminal window or, in the current window, type source .bash_login which will reload your shell and associated environment variables.
You can check that the new variables are set by typing env which will output a list of all the available environment variables. Assuming the new variables are set, you are set to login to the CVS server and checkout a project.
Caveats
The big caveat with this procedure is that you need to login to CVS via the Terminal or a BBEdit worksheet to perform any actions with its CVS tools. If you’re adventurous you could easily write an AppleScript/Perl or Shell script that will do that work for you and make the process easier, but if you aren’t, then just type login cvs and then enter your CVS user password (if you have one).
Keep in mind that many public CVS servers such as those at SourceForge typically provide anonymous access without the need for a password. You can get the full scoop in the case of SourceForge at their site.
The second caveat, and I’m not sure how much this still applies on Panther and with newer versions of BBEdit but you may also need to create a special environment file specifically for GUI apps to use since they can’t inherit these from the shell.
RCEnvironment PreferencePane for Mac OS X
There are two ways of doing this — either through the command line (by creating a file named environment.plist in a new hidden directory in your home folder called .MacOSX), or you can go the easier route and use RCEnvironment which is a preference pane which provides a GUI for creating and editing this file. Unless you know what you’re doing, I’d suggest using the GUI to get started.
Be sure to logout and login again to make the variables available in the GUI environment.
Bonus Tip
Let’s say you want to ensure that all your CVS-related traffic is tunnelled through SSH, all you need to do is add one more line to your .bash_login file and make a small change to your CVSROOT environment variable. That additional line looks like this:
export CVS_RSH=ssh
The revised CVSROOT variable should use this format:
You should not have to login, but you will be prompted for your password each time you launch a new Terminal session.
Additional Information
Here’s a few additional links for everyone’s benefit (myself included). I will likely revise this tutorial at some point, but until then let me know if something doesn’t work for you or if there is anything notable that appears missing or incorrect.
Welcome to the last part in our three-part tutorial series on building a database-driven photo gallery system using PHP and MySQL.
In the first part of this series we looked at defining and setting up the structure of our database tables and briefly discussed how the different fields relate to each other. In the second part, we looked at actually writing the necessary SQL queries required to extract the information from the database. So what now?
If part 2 was about SQL, part 3 is about writing PHP to execute those queries and render the results returned from them. Although this may sound like programming, it’s really not that difficult and I will attempt to explain everything along the way. At this point you may wish to skip to the end and download the final source code examples.
Listing Categories
Following a similar pattern from part 2, our first task is to take the database connection file we created and include that in the main gallery index page. This is done using PHP’s require_once function to essentially merge the two files at runtime helping reduce duplicated code. Our connection file was named connection.php.inc and contained the basic information needed to allow PHP to communicate with MySQL, thus permitting queries to be executed and the results returned to the browser in a viewable form.
The code used to include a file inline inside another PHP file is very simple and looks like this:
<?php
require_once('connection.php.inc');
?>
Place this line as the first line of your HTML file (above the DOCTYPE tag). In fact, all queries will go above that part of the document because they need to be executed before the page is rendered in order for the actual content to be available.
The second step is to take the page used to render the thumbnail view of the individual photo categories. In order to produce clean, readable URLs, this should perhaps all be contained within a directory named galleries and the main thumbnail view in a file named index.php. Be sure to use the .php extension in order to ensure that the PHP parser will do its magic on the server end of things. Alternatively you can change the file extension to html provided you’ve instructed Apache to also parse HTML files.
In the index.php file, directly below the require_once directive, place the following code snippet:
<?php
mysql_select_db($database, $galleries);
$query_rsCategories = "--GET CATEGORY LIST QUERY--";
$rsCategories = mysql_query($query_rsCategories, $galleries)
or die (mysql_error));
$row_rsCategories = mysql_fetch_assoc($rsCategories);
$totalRows_rsCategories = mysql_num_rows($rsCategories);
?>
Since the specific queries were covered in part 2, the above code is using a simple descriptive placeholder. You can see the full code used in the tutorial source download.
Displaying the Category Thumbnails Returned
At this point, if requested, this page should successfully return a set of results but would essentially do nothing since there is currently no display code in the page.
There are a number of ways to structure the display code — tables, lists, etc. In this example, the display code is structured as a simple list. Each list item contains the category thumbnail preview wrapped by a link to display the photo viewer window and the category description. The code will loop through the results returned (1 iteration for each result returned).
After executing the query it’s a good idea to close the connection to MySQL so information isn’t retained in memory unnecessarily. Just below the closing HTML tag on the page, add the following:
<?php mysql_free_result($rsCategories); ?>
That’s everything in the index.php page and it’s time to move on to the photo viewer page to display the large preview along with the associated photo metadata.
Displaying Photos And Meta Data
As outlined earlier this is a two file solution although the code used to build this photo gallery could be merged so that everything is included in the main index file. The second file, named view.php will be used to display the selected category of photos along with the large preview of each. As per the previous code samples, the required PHP code all belongs above the page’s DOCTYPE so that it is parsed and available prior to the page being rendered.
The first step is to again include the require_once statement to initiate the necessary database connection. The first query will take the two variables posted from the index page links and return the category information. The two variables being used are category_id and photo_id. This first query looks like:
SELECT description FROM categories WHERE id = "%s", $colname_rsCategory
The second query returns the actual photo information for a single photo under the specified category — such as the photo ID, filename and comment.
SELECT id, filename, comment FROM photos WHERE category_id = %s
AND id = %s ORDER BY id ASC LIMIT 1
The third and final query returns a data which can be used to create navigation links to browse a single category of photos.
SELECT photos.photo_num, photos.id FROM photos
WHERE photos.category_id = %s ORDER BY photos.id ASC
Each query uses the sprintf function which returns formatted strings. This is where the %s portion of the code comes from.
Putting it all Together
At this point all that’s left to do is wrap up the final pieces of display code, style the layout using CSS and start testing to make sure everything is working as expected. The remainder of this tutorial won’t focus on the visual design aspects but will cover the remaining pieces of display code in the HTML for the view.php file.
To display the category description, simply echo the results of the first query in the page using:
<?php echo $row_rsCategory['description']; ?>
Next, to display the category navigation, create a second list element and loop through the results from the second query, outputting a new list item for each result returned by the query. The code looks like this:
Displaying the photo numbers is also quite easy. We’re going to use a table since technically this is tabular information and semantically we’re not breaking any rules. We also need to apply a horizontal loop to generate the rows and columns for the table. Each item in the table will link to one of the photos returned from the third query. The code looks like this:
Lastly, output the large photo itself along with the associated comment. This is simply a matter of outputting the results of the third query.
Next, we need to display the photo itself and the associated comment meta-data for the photo. Again, this is fairly basic and is just a matter of echoing the results of the query to the page in the appropriate places. It looks something like this:
As in the index.php file, the last bit of code required is to close the connection to MySQL. Below the closing HTML tag, add the following:
And… that’s it. Visually it may not look like much but you now have a simple photo gallery which can be customized to your liking. You can download the full source code for this tutorial below. If you have suggestions, code improvements, additional features or any questions on completing the tutorial, please leave a note in the comments.
In part two of this tutorial series on building your own database-driven photo gallery we’ll cover the SQL queries needed to return the various pieces of information used to generate the gallery display and the individual photo pages.
I’m assuming at this point that you already have MySQL and Apache installed and configured. For more information, see their respective web sites as well as to download the required software for your platform.
Connecting to MySQL
As you might recall from the first part, the database tables allow simple categorization of photos to allow viewing small segments of all the available photos listed in the database.
The first thing needed is to create the actual database connection which will facilitate communication between PHP and the MySQL database which will run the queries and return the results to be rendered by the Apache web server and returned to the browser.
The connection information should generally be separated from the real guts of the application for both clarity and more importantly because it adds a layer of security and could help prevent the access credentials from accidentally being compromised. You may also want to add the necessary information to your Apache .htaccess file(s) to protect this file from being viewable, depending on your level of paranoia. But really, it is a good idea.
This file, named connection.php.inc will contain the necessary database access credentials and set up some variables we can use elsewhere to reliably connect to MySQL and execute queries against the database. This file won’t be used until part 3, but it’s valuable to create it now.
To create the file, using your preferred plain text editor (BBEdit, pico, vim, Dreamweaver, etc.) copy the contents below.
Replace the [YOUR_DB_USERNAME] and [YOUR_DB_PASSWORD] with the appropriate details for your system.
Return Photo Categories
The first query we need to use returns a list of the categories listed in the database along with the auxiliary information used to display each category along with a link to launch the photo viewer. For the time being we’ll just focus on the SQL and leave the presentation code to part 3.
SELECT DISTINCT photos.id, photos.category_id, categories.preview, categories.description
FROM photos, categories WHERE photos.category_id = categories.id AND photos.filename
LIKE '%01.jpg' ORDER BY filename ASC
This first query returns the id, category_id, preview and description for each category. The two ID values are passed on to the viewer queries to locate the correct photos for the selected category. A small preview is displayed for each category using the preview field along with the description data for the category.
The query makes use of a simple wildcard to locate the appropraite preview images. The % character is used to ensure the query returns anything matching filename01.jpg or anotherfile01.jpg but not morefiles1.jpg.
Everything needed to create a simple category-based thumbnail preview for each category of photos will be returned by that one query and we can now move on to the main photo viewer file — view.php.
Photo Enlargement
This second file (view.php), the photo viewer is built based on three queries. The first returns the category descriptions, the second returns the large photo to be displayed and the last will return a list of all the photos associated with the selected category.
Return the Category Name
To return the selected category information, we are passing the category_id value from the main thumbnails page which is reflected in the query.
SELECT description FROM categories WHERE category_id = "%s", $colName_rsCategory
Return a single Large Photo
To find and return a single full-size photo and its associated metadata, the SQL query requires two values — the category_id and the photo_id from the thumbnails display page. Because we only want to render a single photo, we also need to restrict the results returned to a single entry.
SELECT id, filename, height, width, comment
FROM photos WHERE photos.category_id = %s AND id = %s
ORDER BY id ASC LIMIT 1
This query is executed each time a user clicks on a link from the returned list of photos in a selected category.
Return a Category’s Photos
The final query returns a list of every photo associated with a single category. As before, the category_id value is used to return the relevant results.
SELECT photo_gallery.photo_num, photo_gallery.photo_id
FROM photo_gallery WHERE photo_gallery.photo_category_id = %s
ORDER BY photo_gallery.photo_id ASC
Well, that’s it for now class. In part three we’ll tie everything together and show how it all works along with a few samples of the presentation code used here. At that point I’ll also make source code available for the gallery project. See you next time!
Welcome to part one of a three part tutorial series on how to build a dynamic, database-driven image gallery. You should be able to repurpose these instructions based on a different visual design since I’m not going to cover anything specific with regards to the visual aspects of the layout.
The tutorial has been broken down as three pieces for simplicity. Although we’ll only be dealing with two files and I could combine all of the back-end scripts as one file, for aesthetic reasons I’ll keep things separate. Let’s get started…
Setup
To complete the tutorial, you will need to have two pieces of software installed and running on your computer or a server somewhere. For the database component, you will need the community edition of MySQL installed. Version 4.0 or newer should all work. For the web server, I recommend using the Apache web server, included out of the box with Mac OS X. You will also need to ensure that the PHP module for Apache is enabled and configured appropriately. Follow any provided documentation for specifics on security-related issues.
Setting up the MySQL Database
Before doing anything else, the database source needs to be created for this tutorial. To keep things easy, I’ll also assume you set up phpMyAdmin to manage your databases.
Login to phpMyAdmin in your web browser.
Create a new database and name it photo_gallery. We’ll make reference to this later once we start developing the SQL queries that will bring things to life.
Select the database you just created from the pop-up menu or listing on the left sidebar of phpMyAdmin. In the right frame, click on the SQL tab. This will open up the SQL editor view.
To add the necessary tables to the photo_gallery database, copy the SQL queries below into the SQL editor window and press the Go button.
CREATE TABLE categories (
id int(11) unsigned NOT NULL auto_increment,
description varchar(100) NOT NULL default '',
preview varchar(64) NOT NULL default '',
PRIMARY KEY (id)
) TYPE=MyISAM COMMENT='Gallery Categories';
CREATE TABLE photos (
id int(11) unsigned NOT NULL auto_increment,
filename varchar(64) NOT NULL default '',
comment varchar(255) default NULL,
category_id int(11) unsigned NOT NULL default '0',
PRIMARY KEY (id)
) TYPE=MyISAM COMMENT='Gallery Images';
Assuming the SQL is executed successfully, you can close the SQL editor window.
Now that the database tables have been created, you’re ready to start adding data. Start by creating a series of categories. Enter a description for each. The required ID field will be automatically created since the table is set to auto-increment the category_id field.
Once you’ve created a few categories, you can start adding photos and assigning them to the previously created categories. The photo_filename field should contain the actual name of the image file including the file extension (eg. .jpg, .gif, .png). The photo_comment field is used to add a short description of the photo and the category_id field is a foreign key field and should contain the appropriate ID value from the categories table. This allows us to provide a simple category mechanism, though it currently only allows assignment of a single category.
Questions? Stuck?
If you get stuck, leave a comment and I will (within reason) try to provide adequate assistance.
Having had the benefit of using Mac OS X Panther since it’s introduction at WWDC back in June of 2003, I’ve had a bit longer than the average user to tinker, poke around and undoubtedly break things. One welcome addition in Panther has been the inclusion of X11 (XFree86), albeit one that is not installed by default (it’s included on Install Disc 3). X11 is not something terribly useful to most users, which is why it’s an optional install, but for those that do, having the software available saves us from using other third-party implementations.
The X11 environment brings a wide variety of X-Windows-based GUI applications running on other Macs, Linux or other *nix flavours to your desktop.
For myself, this is extremely useful since I need access to server tools which would otherwise be difficult to access remotely, leaving me stuck sitting in freezing cold server rooms. Not much fun for anything longer than 5 minutes. While I try to do as much admin work as possible through the commandline, sometimes it’s just faster and easier to use a GUI. The big difference, though one which likely only affects a small selection of apps is that Apple’s X11 implementation is integrated with the Quartz graphics engine in Mac OS X itself.
A good example of how I’m using X11 in a real-world situation is using rdesktop to access Windows Terminal Services, a replacement option for Microsoft’s own Remote Desktop application to manage an Exchange Server run out of Chicago, IL. One less piece of proprietary Microsoft software is always a good thing in my books.
I’m also using X11 to help manage a few IRIX-based SGI servers. Combining SSH and X-Windows on Mac OS X is a great set of tools to securely access GUI services running on the SGI servers. For example, once I SSH into the server, it’s just a matter of typing toolchest to bring up the GUI tools on my Mac in the X11 environment.
Setting Up X11
First, make sure you’ve installed X11. You’ll find it in your Applications/Utilities folder if it has been installed otherwise get installing (Disc 3 in Panther). In order to continue you’ll also want to be comfortable working in the Terminal. The instructions will be reasonably verbose in case you’re not quite a Unix guru.
Launch the Terminal application (found in your Utilities folder).
Start by making a copy of the /etc/sshd_config file which is the configuration file for the SSH daemon.
sudo cp /etc/sshd_config sshd_config.orig
The sudo command will allow you to execute the cp (copy) command with root permissions giving you full read/write access to the filesystem. You will need an administrator password. Enter it when prompted.
Edit the original file we just made a backup copy of using your preferred text editor. Be sure to use a plain text editor such as BBEdit, pico or vi in order to preserve the integrity of the file. In this case, using pico.
sudo pico /etc/sshd_config
The contents of the sshd_config file should now be visible in your Terminal window. Locate that line that reads #X11Forwarding no and change it to remove the octothorp character at the beginning of the line to activate it. We also need to change the line to replace no with yes.
The final line should look like: X11Forwarding yes
Save your changes by pressing Control-X which will display a save prompt. Press ‘y’ (or Return) to accept and then press Return a second time to select the previous filename. This will save the file and return you to a new Terminal prompt.
Restart the SSH daemon. In the System Preferences under Sharing, toggle the Remote Login checkbox which will restart the SSH background process. You should now be ready to connect to your computer and run X11 applications remotely. So, now how exactly does one do this?
Connecting To Remote Servers
Now that we have X11 configured, if you have a second computer available you can test a remote connection.
Open X11 in your Utilities folder. A window that looks deceptively like the Terminal will open.
In the new xterm window, use the following command to remotely login to a second computer (Mac OS X, Linux or other *nix): ssh -X [USERNAME][IP_ADDRESS]@@.
Replace @ and [IP_ADDRESS]@ with the appropriate values and enter a password for the requested remote account. Assuming you are successful here, pass go and collect $200 and go to step 3.
Once remotely logged onto the second computer you’re ready to run one of the simple X11 applications included with Mac OS X. Try these on for size:
/usr/X11R6/bin/xeyes
/usr/X11R6/bin/xclock
Type exit in the xterm window when you are done. This will disconnect you from the remote server.